
Les interruptions
Ce graphique montre les exécutions au fil du temps.
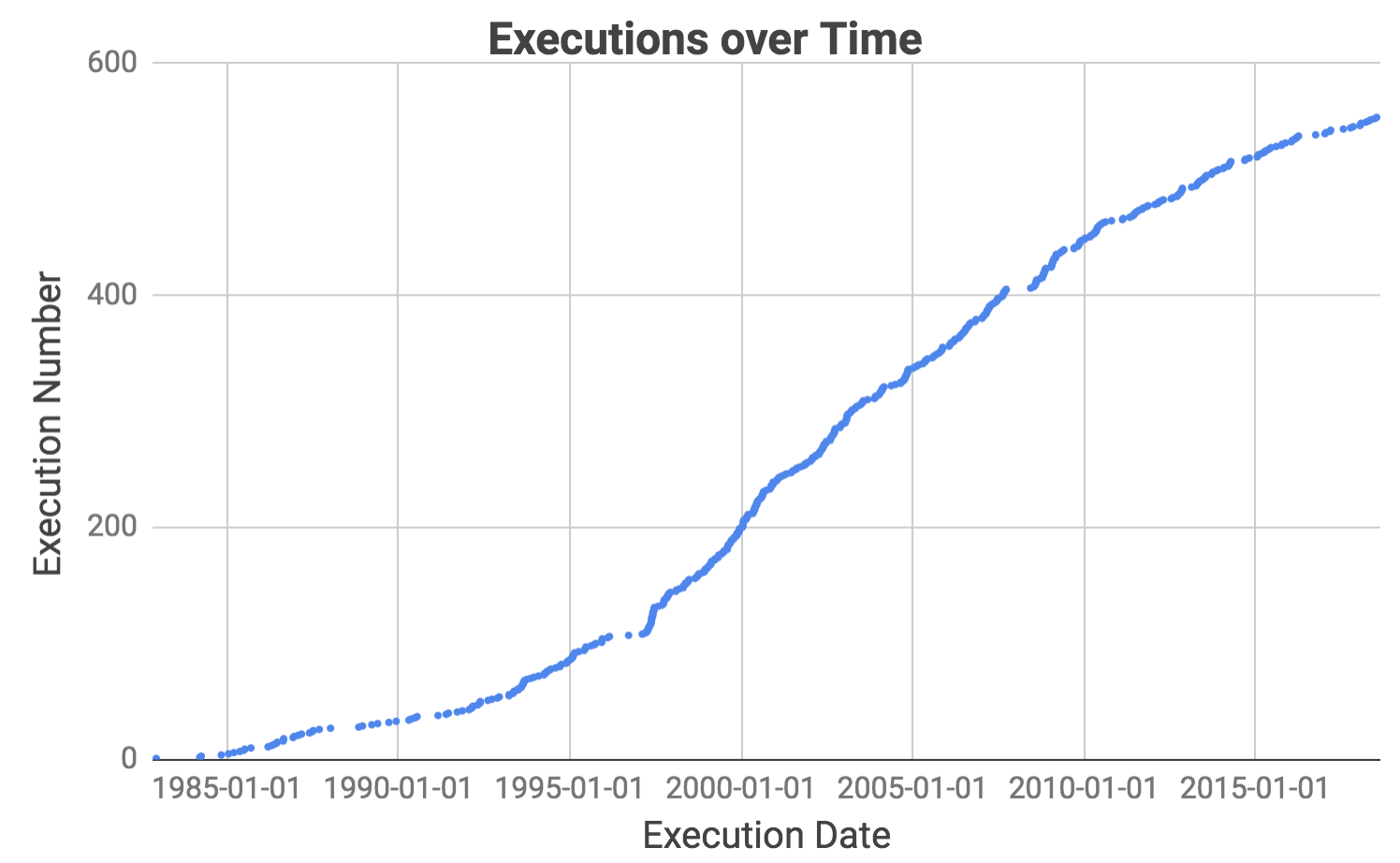 Il faut noter qu’il y a eu plusieurs périodes prolongées où aucune exécution n’a eu lieu. Notre objectif est de déterminer exactement quand ils ont été et d’en rechercher les causes.
Il faut noter qu’il y a eu plusieurs périodes prolongées où aucune exécution n’a eu lieu. Notre objectif est de déterminer exactement quand ils ont été et d’en rechercher les causes.
Notre stratégie est de mettre la table dans un état où chaque ligne contient également la date d’exécution avant elle. Nous pouvons alors trouver la différence de temps entre les deux dates, les classer par ordre décroissant et lire les hiatuses les plus longues.
Les réflexions sur les joints
Aucune des techniques que nous avons apprises jusqu’à présent ne convient ici. Notre table souhaitée a la même longueur que la table originale de executions , nous pouvons donc exclure les agrégations qui produisent une table plus petite. Nous avons appris dans le chapitre de Beazley que les opérations de rangées nous limitent à travailler avec l’information qui y sont déjà. Cependant, la date de l’exécution précédente se trouve en dehors d’une ligne donc nous devons utiliser JOIN pour apporter les informations supplémentaires.
Supposons que l’information supplémentaire que nous voulons existe dans une table appelée previous (« précédent ») qui a deux colonnes : (ex_number, last_ex_date) (« (nombre d’exécution, dernière date d’exécution) »). Nous pourrions exécuter la requête suivante pour terminer notre tâche :
SELECT
last_ex_date AS start,
ex_date AS end,
ex_date - last_ex_date AS day_difference
FROM executions
JOIN previous
ON executions.ex_number = previous.ex_number
ORDER BY day_difference DESC
LIMIT 10
Le bloc JOIN est au centre de cette section. Plutôt que de le voir comme une ligne à part entière, il est souvent utile de le regarder comme suit :
 Ceci met l’accent sur la façon dont
Ceci met l’accent sur la façon dont JOIN crée une grande table combinée qui est ensuite introduite dans le bloc FROM comme n’importe quelle autre table.
Désambiguïsation des colonnes
La requête ci-dessus est également remarquable car la clause executions.ex_number = previous.ex_number utilise le format <table>.<column> pour spécifier les colonnes. Cela n’est nécessaire ici que parce que les deux tables ont une colonne appelée ex_number.
Les types de joints
Le bloc JOIN prend la forme <table1> JOIN <table2> ON <clause>. La clause fonctionne de la même façon que dans WHERE <clause>. Autrement dit, c’est une instruction qui évalue à vrai ou faux, et chaque fois qu’une ligne de la première table et une autre de la deuxième ligne avec la clause étant vrai, les deux sont appariés :

Mais qu’arrive-t-il aux lignes qui n’ont pas de correspondance ? Dans ce cas, la table previous n’avait pas de ligne pour l’exécution numéro 1 car il n’y a pas d’exécutions avant celle-ci.
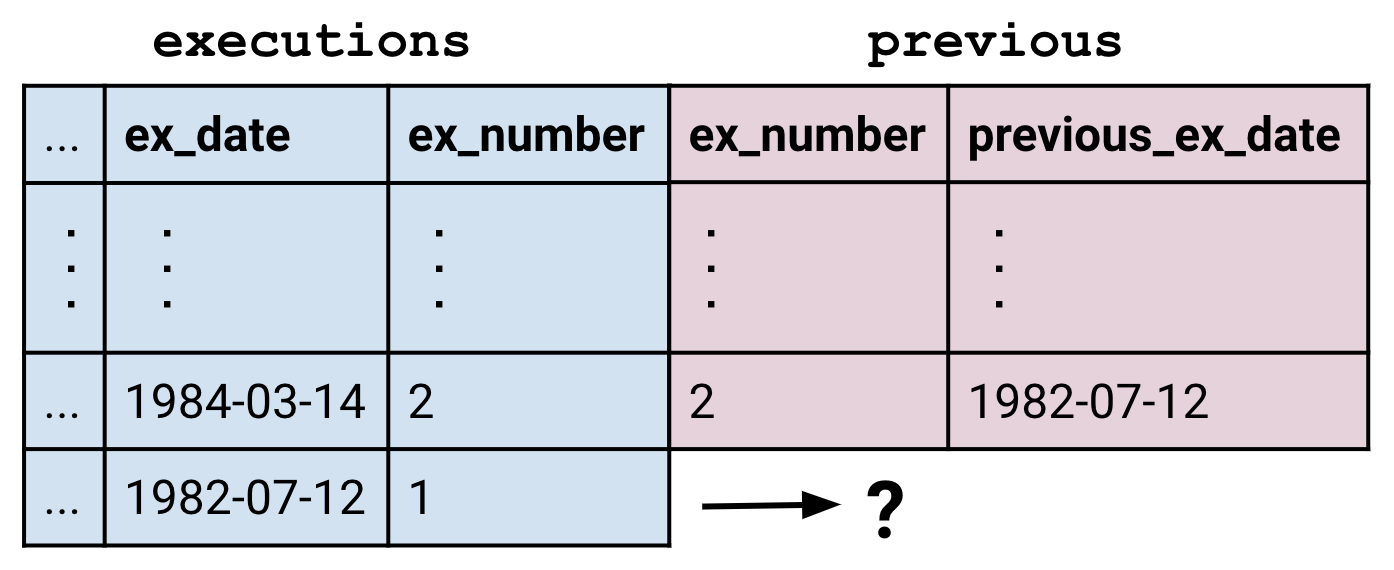
La commande JOIN exécute par défaut ce qu’on appelle une « inner join » (« la jointure interne ») dans laquelle des lignes non appariées sont supprimées.
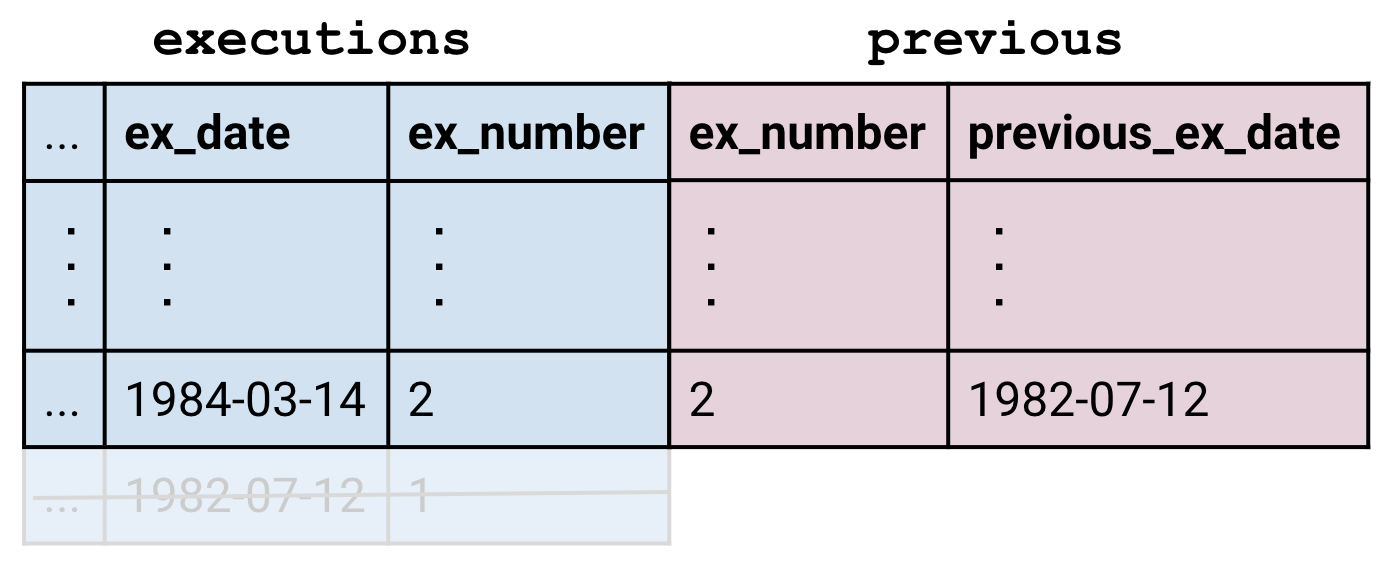
Pour préserver toutes les lignes du tableau de gauche, on utilise un LEFT JOIN (« la jointure à gauche ») à la place du JOIN basique. Les parties vides de la ligne sont laissées seules, ce qui signifie qu’elles sont évaluées à NULL.
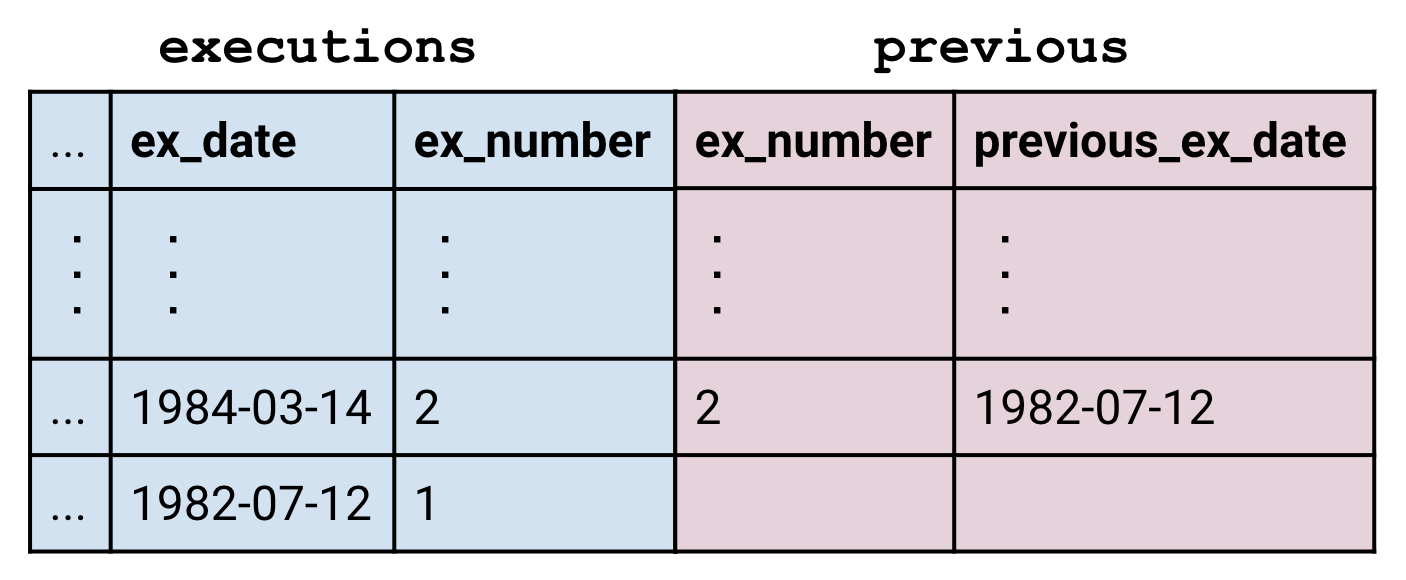
Le RIGHT JOIN (« la jointure à droit ») peut être utilisé pour conserver les lignes non correspondantes dans la table de droite, et le OUTER JOIN ( « la jointure externe ») peut être utilisée pour conserver les lignes non correspondantes dans les deux.
La dernière subtilité est de gérer plusieurs correspondances. Supposons que nous ayons une table duplicated_previous (« précédente_dupliquée ») qui contient deux copies de chaque ligne de la table previous. Chaque ligne d’exécution correspond maintenant à deux lignes dans duplicated_previous.
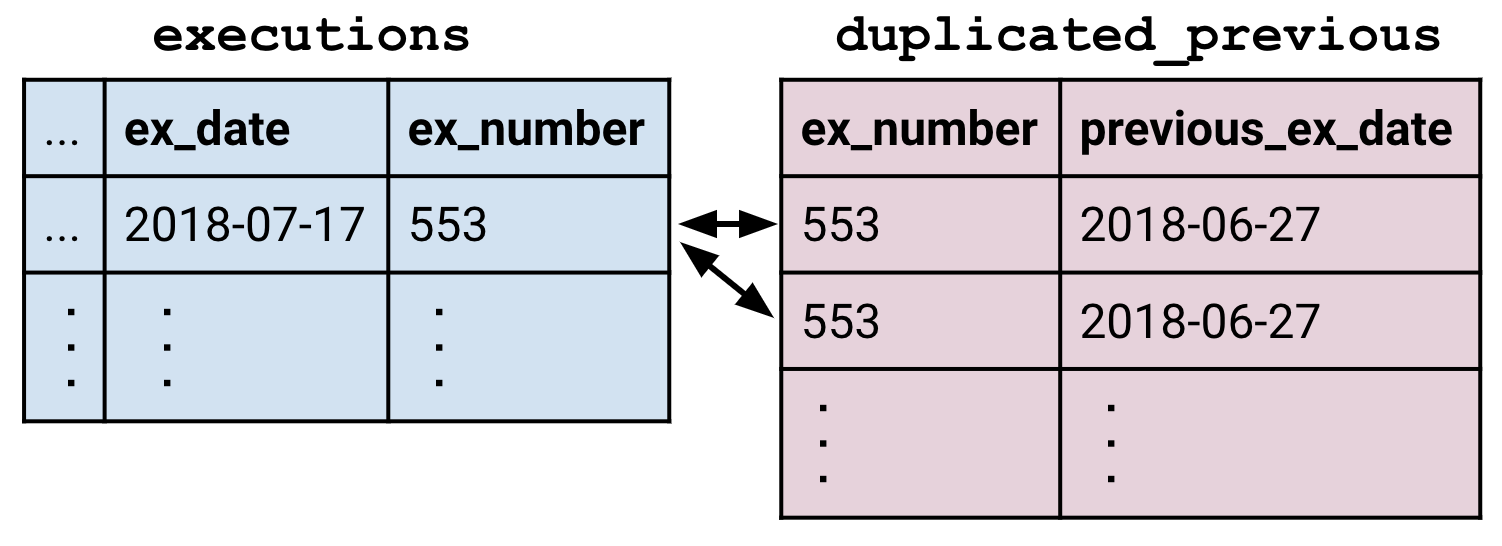
La jointure crée suffisamment de lignes d’exécution pour que chaque ligne correspondante de duplicated_previous ait son propre partenaire. De cette façon, les jointures peuvent créer des tables plus grandes que leurs constituants.
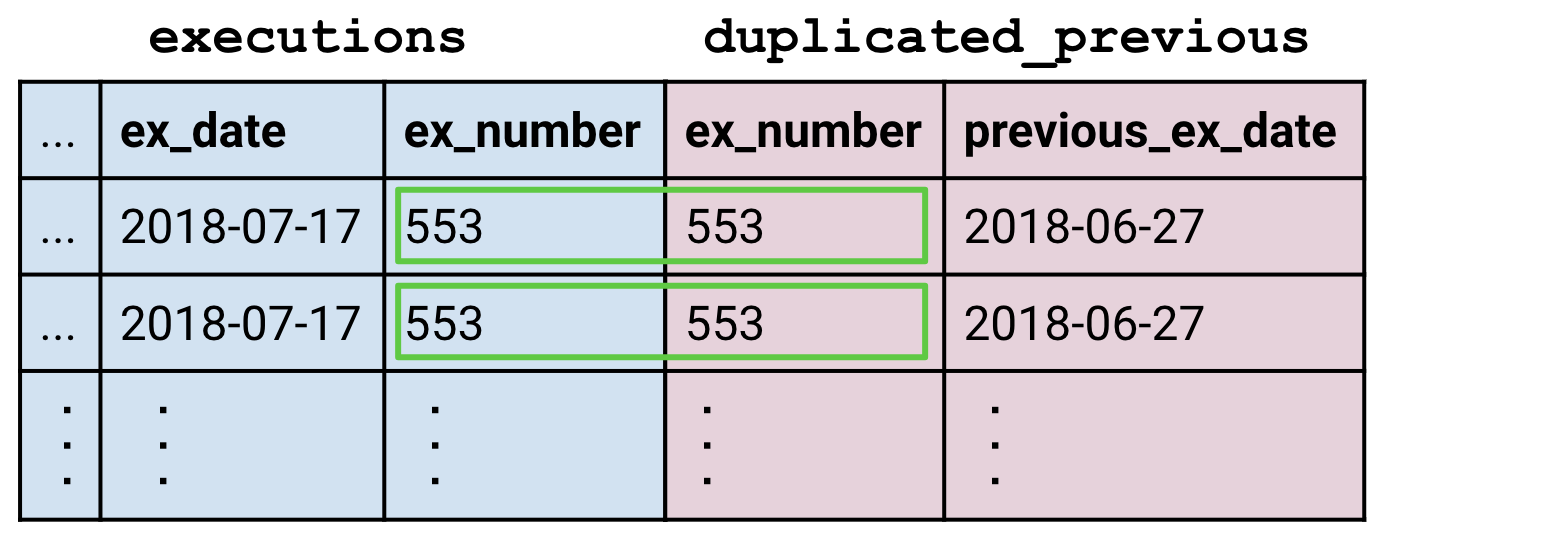
Les dates
Faisons une pause des jointure pendant un moment et regardons cette ligne dans notre modèle de requête :
ex_date - last_ex_date AS day_difference
(la date d’exécution - la dernière date d’exécution AS la différence entre des jours)
Nous avons fait une grande hypothèse que nous pouvons soustraire des dates les uns des autres. Mais imaginez que vous êtes l’ordinateur recevant une ligne comme celle-ci. Renvoyez-vous le nombre de jours entre les dates? Pourquoi pas des heures ou des secondes? Pour aggraver les choses, SQLite n’a pas de date ou d’heure (contrairement à la plupart des autres dialectes SQL) donc les colonnes ex_date et last_ex_date ressemblent à des chaînes ordinaires. On vous demande effectivement de faire 'hello' - 'world'. Qu’est-ce que cela veut dire ?
Heureusement, SQLite contient un tas de fonctions pour dire à l’ordinateur : « Hé, ces chaînes que je vous passe contiennent en fait des dates ou des heures. Agissez sur eux comme vous le feriez pour une date. »
Les auto-jointures
Avec ce que nous avons appris sur les dates, nous pouvons corriger notre modèle de requête :
SELECT
last_ex_date AS start,
ex_date AS end,
JULIANDAY(ex_date) - JULIANDAY(last_ex_date)
AS day_difference
FROM executions
JOIN previous
ON executions.ex_number = previous.ex_number
ORDER BY day_difference DESC
LIMIT 5
L’étape suivant est à créer la table previous
Nous pouvons maintenant imbriquer cette requête dans notre modèle ci-dessus :
La table previous est dérivé de la table executions, donc nous sommes effectivement en train d’ajouter executions à elle-même. On appelle cela une « auto-jointure » et c’est une technique puissante qui permet aux lignes d’obtenir des informations à partir d’autres parties de la même table.
Nous avons créé le tableau previous pour clarifier l’objectif qu’il sert. Mais nous pouvons écrire la requête de manière plus élégante en joignant directement à elle-même la table executions.
Nous pouvons maintenant utiliser les dates précises des cessations pour rechercher ce qui s’est passé au cours de chaque période. Dans les années qui ont immédiatement suivi la levée de l’interdiction de la peine capitale, il y a eu de longues périodes sans exécution en raison du faible nombre de condamnations à mort, ainsi que des contestations juridiques de la nouvelle décision. Nous excluons donc les intervalles antérieurs à 1993 et nous concentrons sur deux cessations majeures depuis.
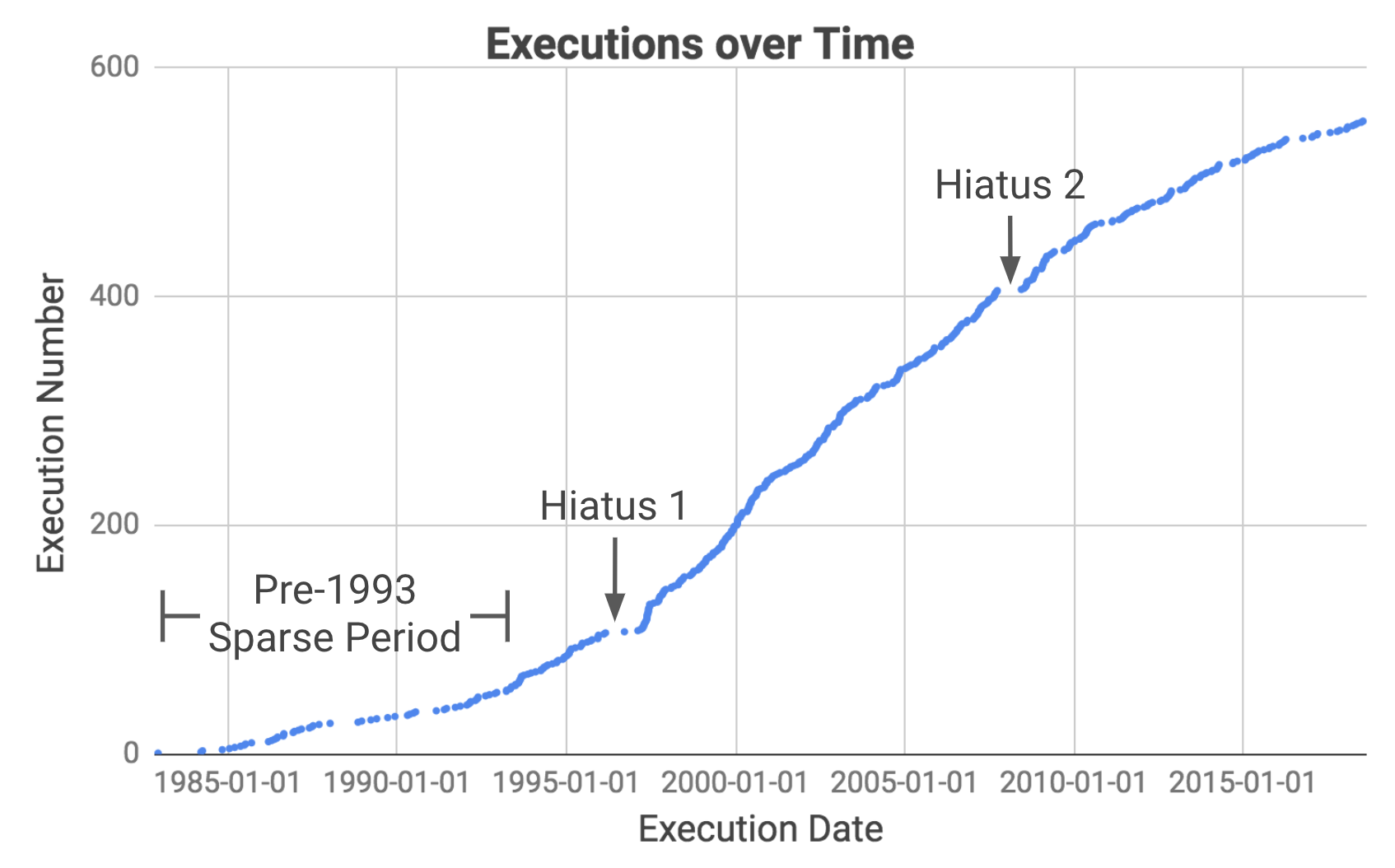
La première interruption est due à des contestations juridiques de Antiterrorism and Effective Death Penalty Act of 1996, créée en réponse aux attentats de 1993 au World Trade Center et de 1995 à Oklahoma City. La loi a limité le processus d’appel pour rendre la peine de mort plus efficace, en particulier dans les cas de terrorisme (source).
Le deuxième interruption a été causée par un sursis décrété par la Cour suprême pendant qu’elle examinait l’affaire Baze c. Rees, qui portait sur la question de savoir si l’injection létale viole le huitième amendement interdisant les « peines cruelles et inusitées ». Cela a affecté les exécutions à travers l’Amérique parce que la plupart des états utilisaient le même cocktail de drogues que le Kentucky. La Cour suprême a finalement confirmé la décision de la cour du Kentucky et les exécutions ont repris au Texas quelques mois plus tard.
Les récapitulatifs
La grande idée derrière les JOINs a été de créer une table augmentée parce que l’original ne contenait pas les informations dont nous avions besoin. Il s’agit d’un concept puissant car il nous libère des limitations d’une seule table et nous permet de combiner plusieurs tables de manière potentiellement complexe. Nous avons également constaté qu’avec cette complexité supplémentaire, la tenue de livres minutieuse devient importante. Les tables d’alias, le changement de nom des colonnes et la définition de bonnes clauses de JOIN ON sont autant de techniques qui nous aident à maintenir l’ordre.